Home / Docs / Release 0.6.2 / Tutorials / Self-healing / Up-scale with Dynatrace
Up-scale with Dynatrace
Demonstrates how to use the self-healing mechanisms of Keptn to solve a problem in a production stage by providing automated upscaling.
About this tutorial
In this tutorial, you will learn how to use the capabilities of Keptn to provide self-healing for an application without modifying code. The following tutorial will scale up the pods of an application if the application undergoes heavy CPU saturation.
Prerequisites
- See Self-healing.
- Double-check that you have disabled frequent issue detection within Dynatrace.
Configure monitoring
To inform Keptn about any issues in a production environment, monitoring has to be set up. The Keptn CLI helps with the automated setup and configuration of Dynatrace as the monitoring solution running in the Kubernetes cluster.
To add these files to Keptn and to automatically configure Dynatrace, execute the following commands:
Make sure you are in the correct folder of your examples directory:
cd examples/onboarding-cartsConfigure remediation actions for up-scaling based on Dynatrace alerts:
keptn add-resource --project=sockshop --stage=production --service=carts --resource=remediation.yaml --resourceUri=remediation.yamlConfigure Dynatrace with the Keptn CLI:
keptn configure monitoring dynatrace --project=sockshop
Click here to inspect the file that has been added.
remediation.yaml
remediations:
- name: response_time_p90
actions:
- action: scaling
value: +1
- name: Response time degradation
actions:
- action: scaling
value: +1
Configure Dynatrace problem detection with a fixed threshold: For the sake of this demo, we will configure Dynatrace to detect problems based on fixed thresholds rather than automatically.
Log in to your Dynatrace tenant and go to Settings > Anomaly Detection > Services.
Within this menu, select the option Detect response time degradations using fixed thresholds, set the limit to 1000ms, and select Medium for the sensitivity as shown below.
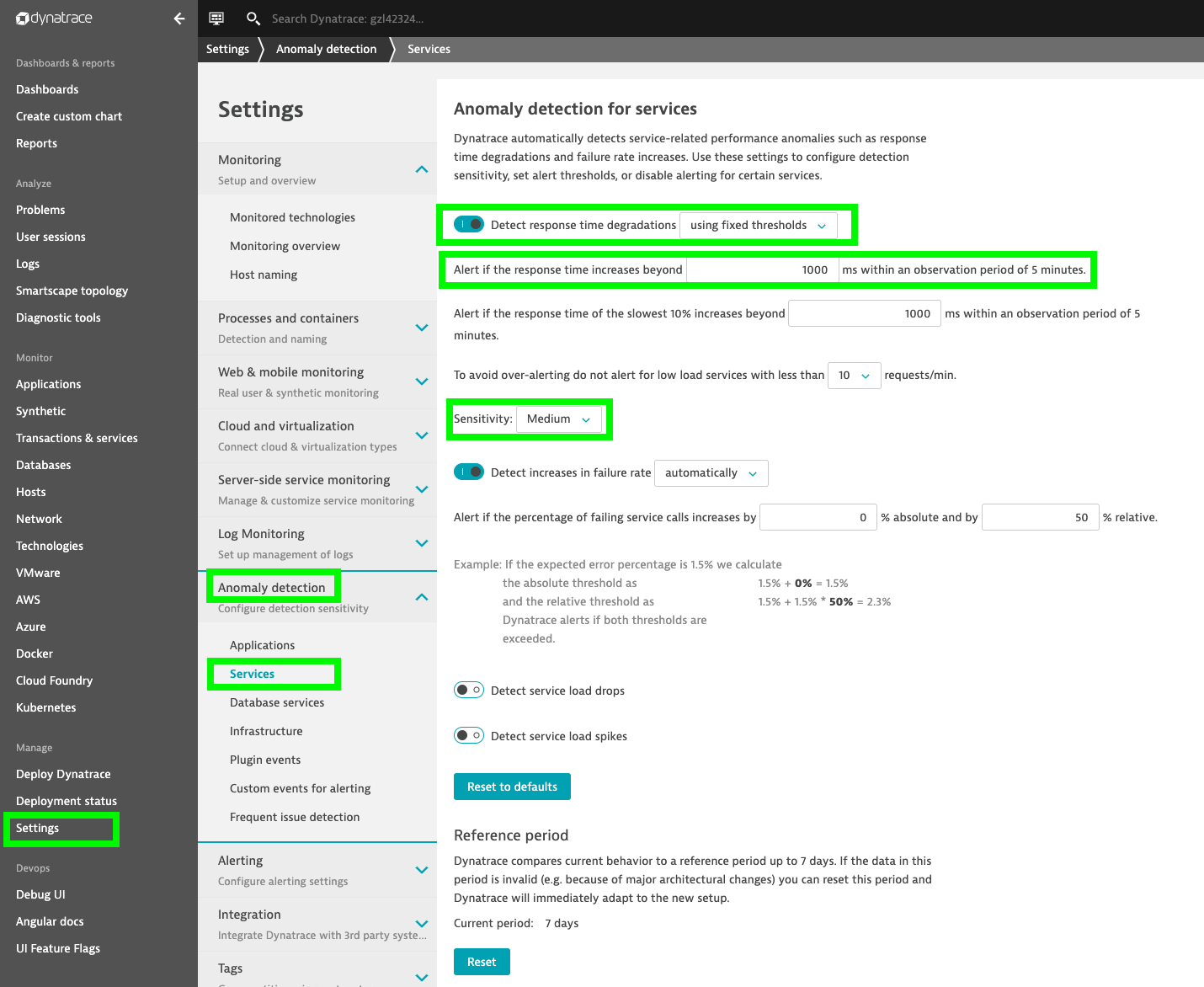
Anomaly detection settings
Note: You can configure those fixed thresholds per service instead of globally.
Run the tutorial
Generate load for the service
To simulate user traffic that is causing an unhealthy behavior in the carts service, please execute the following script. This will add special items into the shopping cart that cause some extensive calculation.
Move to the correct folder:
cd ../load-generation/binStart the load generation script depending on your OS (replace _OS_ with linux, mac, or win):
./loadgenerator-_OS_ "http://carts.sockshop-production.$(kubectl get cm keptn-domain -n keptn -o=jsonpath='{.data.app_domain}')" cpuOptional: Verify the load in Dynatrace
In your Dynatrace Tenant, inspect the Response Time chart of the correlating service entity of the carts microservice. Hint: You can find the service in Dynatrace easier by selecting the management zone Keptn: sockshop production:
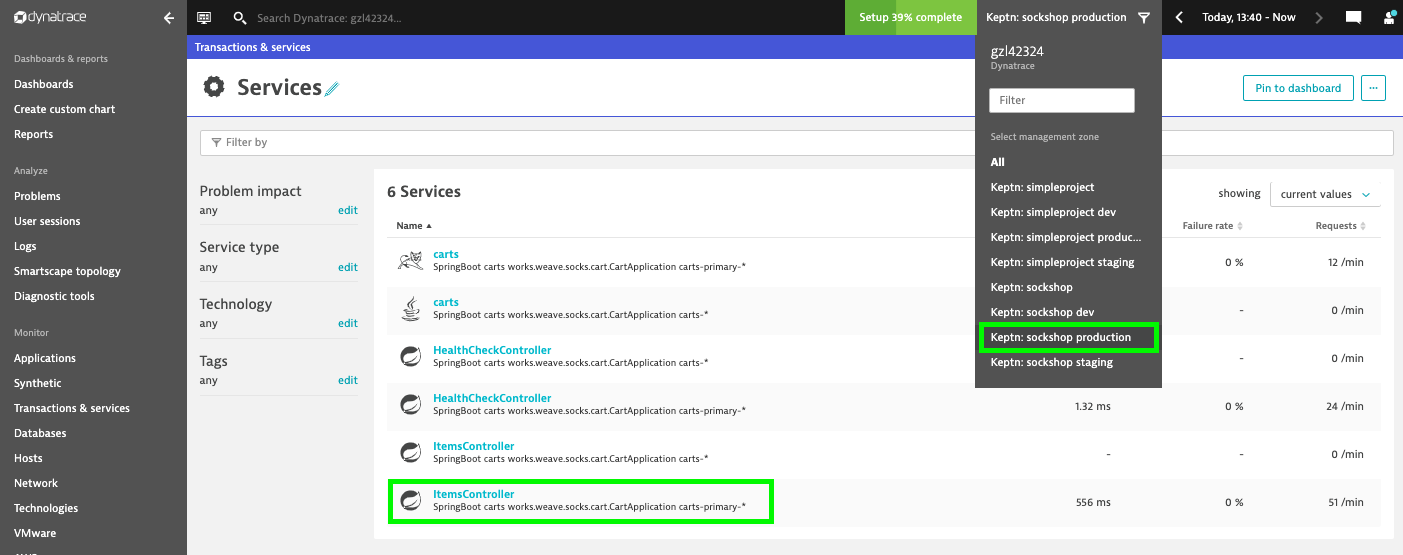
Select the ItemsController service in the management zone 'Keptn: sockshop production' 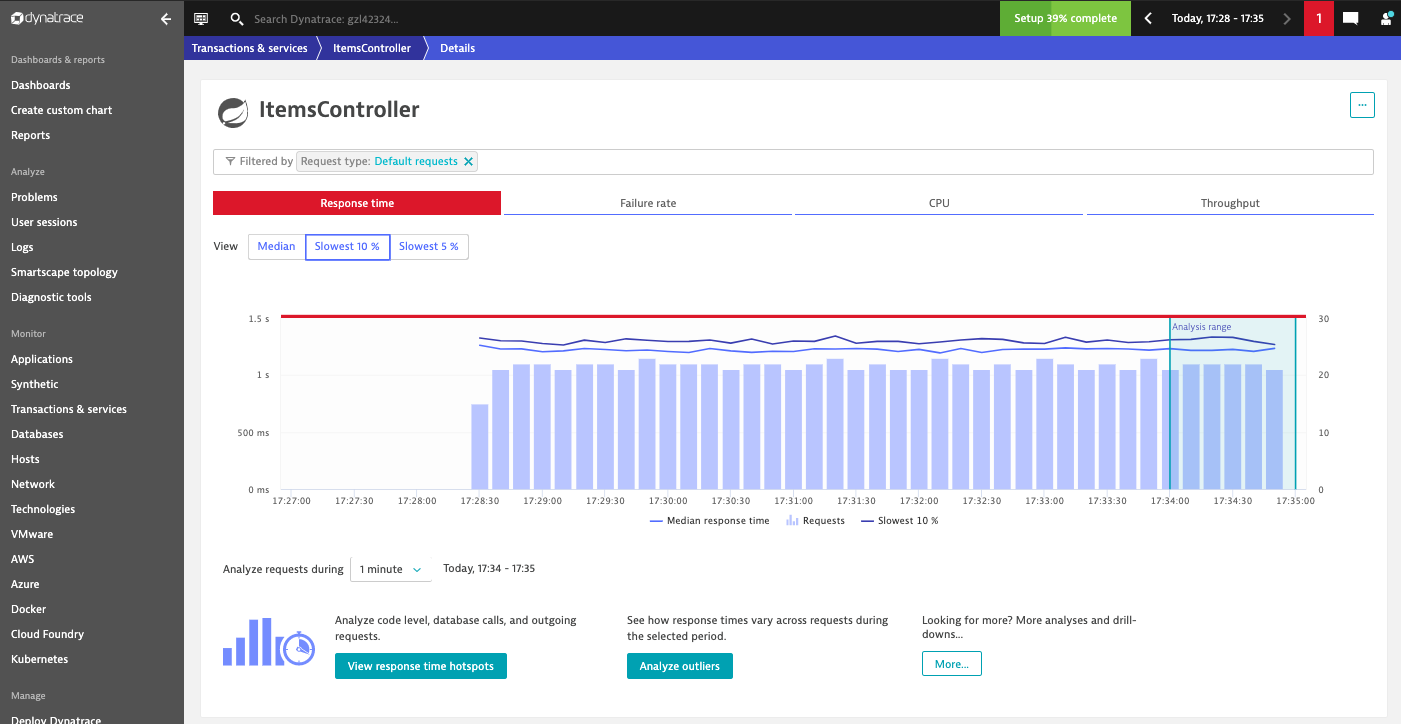
Response Time Series in Dynatrace
As you can see in the time series chart, the load generation script causes a significant increase in the response time.
Watch self-healing in action
After approximately 10-15 minutes, Dynatrace will send out a problem notification because of the response time degradation.
After receiving the problem notification, the dynatrace-service will translate it into a Keptn CloudEvent. This event will eventually be received by the remediation-service that will look for a remediation action specified for this type of problem and, if found, execute it.
In this tutorial, the number of pods will be increased to remediate the issue of the response time increase.
Check the executed remediation actions by executing:
kubectl get deployments -n sockshop-productionYou can see that the
carts-primarydeployment is now served by two pods:NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE carts-db 1 1 1 1 37m carts-primary 2 2 2 2 32mBesides, you should see an additional pod running when you execute:
kubectl get pods -n sockshop-productionNAME READY STATUS RESTARTS AGE carts-db-57cd95557b-r6cg8 1/1 Running 0 38m carts-primary-7c96d87df9-75pg7 2/2 Running 0 33m carts-primary-7c96d87df9-78fh2 2/2 Running 0 5mTo get an overview of the actions that got triggered by the response time SLO violation, you can use the Keptn Bridge. If you have not exposed the Bridge yet, execute the following command:
keptn configure bridge --action=exposeThe Keptn Bridge is then available on: `https://bridge.keptn.YOUR.DOMAIN/.
In this example, the bridge shows that the remediation service triggered an update of the configuration of the carts service by increasing the number of replicas to 2. When the additional replica was available, the wait-service waited for 10 minutes for the remediation action to take effect. Afterwards, an evaluation by the lighthouse-service was triggered to check if the remediation action resolved the problem. In this case, increasing the number of replicas achieved the desired effect since the evaluation of the service level objectives has been successful.
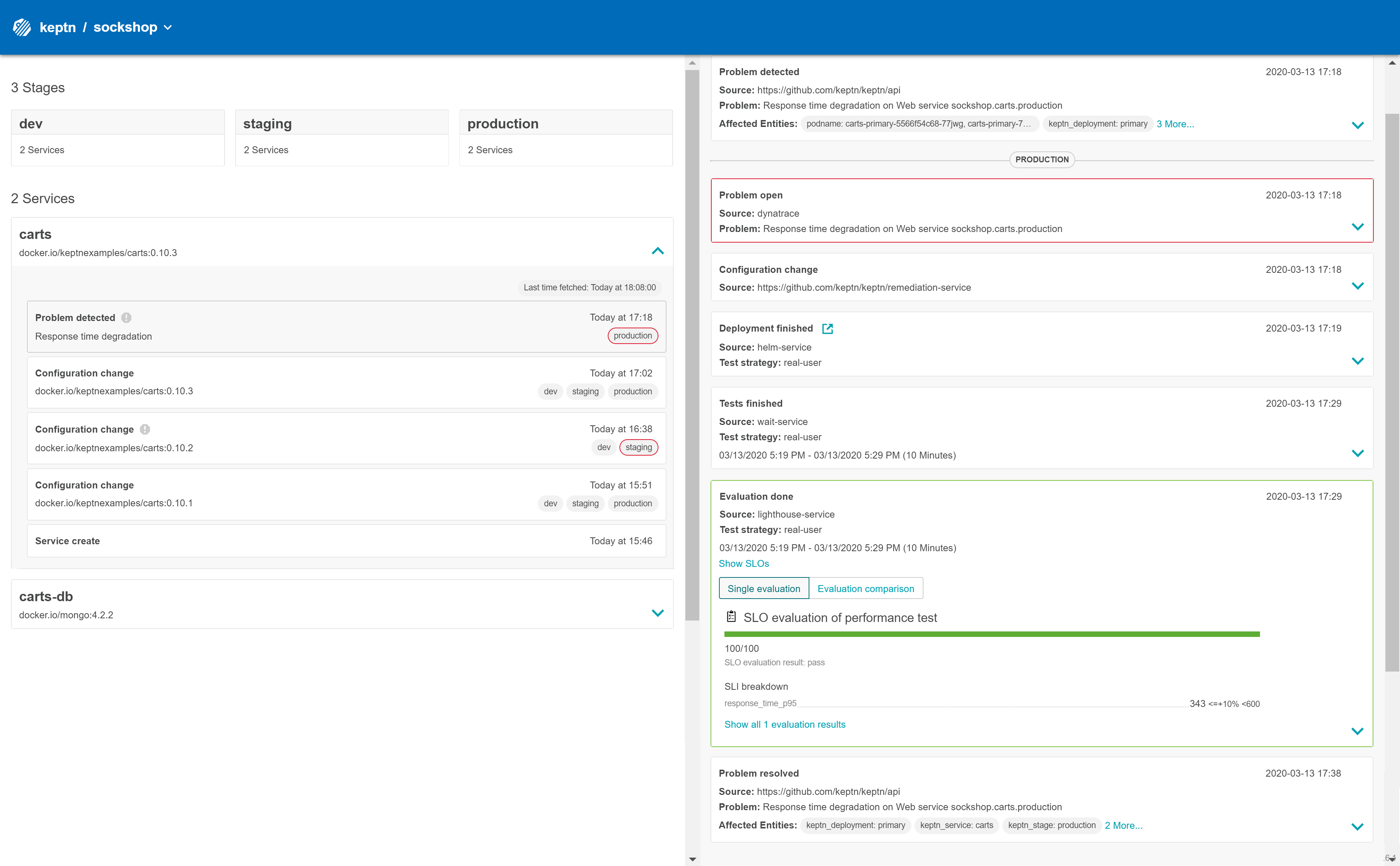
Problem event in Keptn's Bridge Furthermore, you can see how the response time of the service decreased by viewing the time series chart in Dynatrace:
As previously, go to the response time chart of the ItemsController service. Here you will see that the additional instance has helped to bring down the response time. Eventually, the problem that has been detected earlier will be closed automatically.
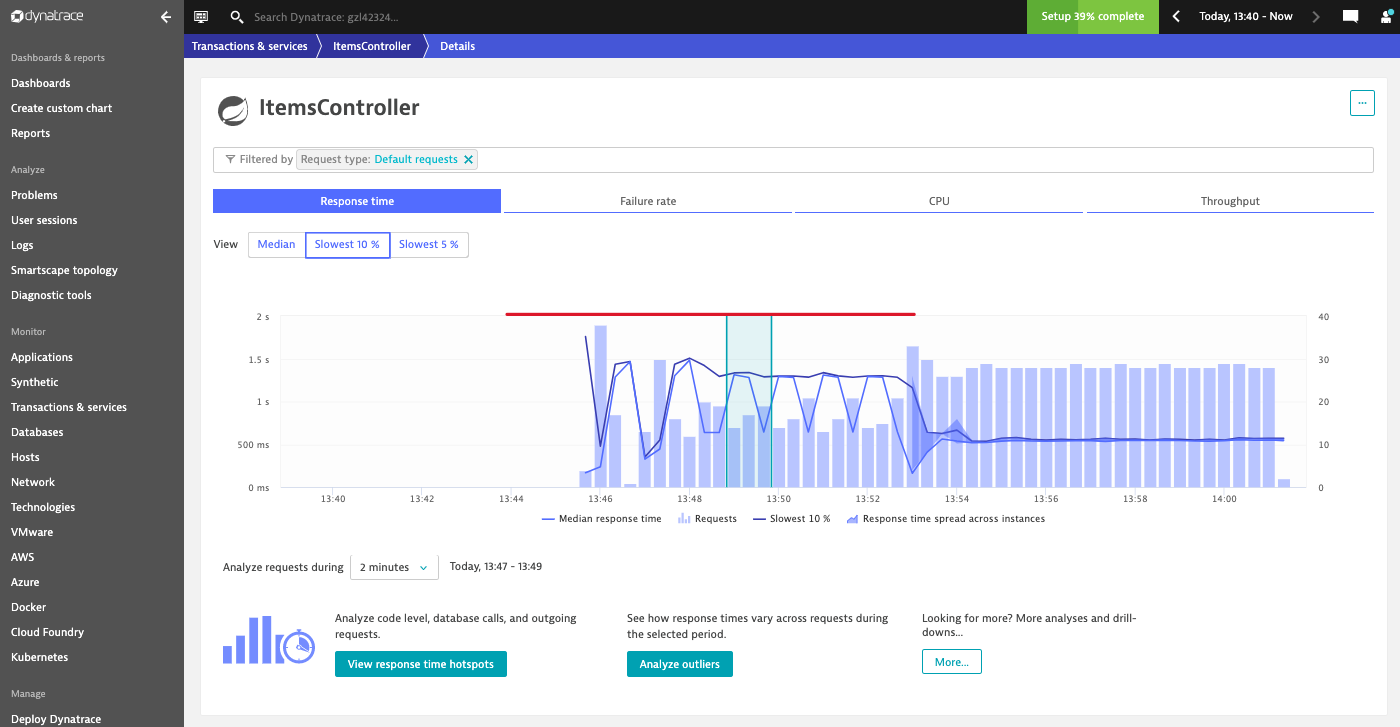
Response Time Series in Dynatrace
Built with  by Dynatrace
by Dynatrace